
|
We are pleased to announce preview support in HPCBOX for NVIDIA A-100 powered NDv4 instances on Microsoft Azure, specifically Standard_ND96asr_v4. As per Microsoft’s documentation, the ND A100 v4-series uses 8 NVIDIA A100 TensorCore GPUs, each with a 200 Gigabit Mellanox InfiniBand HDR connection and 40 GB of GPU memory.
Introduction
This blog post will be the first in what will hopefully be a two-part series with more information to share later. But, for now, using these machines was so exciting that an initial post was well worth it.
Drizti’s HPCBOX platform delivers a fully interactive turn key HPC solution targeting end-users directly and comes with expert HPC support offered by Drizti. This gives end-users a single point of contact and a fully integrated solution which has already been optimized or can be optimized by our HPC experts in collaboration with users for custom codes which are developed in-house. The NDv4 instances are cutting edge and Microsoft Azure is probably the only public cloud vendor to offer this kind of a machine configuration for applications that can effectively use multiple GPUs. The screenshot below shows the output of nvidia-smi on one of these instances. 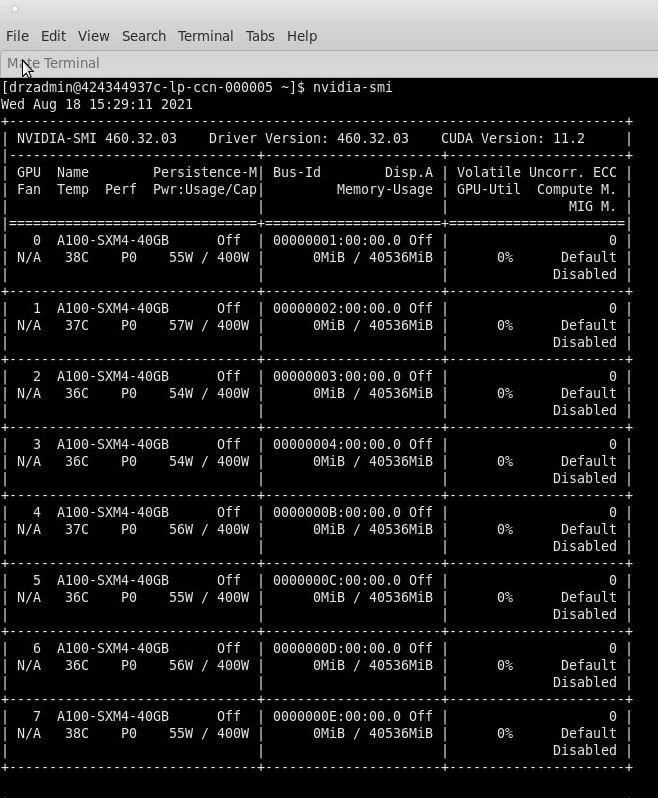
Not one but many for extreme scale
At Drizti, we like to make sure we can offer a truly super scale computing setup with a fully interactive Personal Supercomputing experience. We want our users to be able to use supercomputers in the same way as they use their PCs or workstations and eliminate the learning curve and time wasted waiting for efficient use of supercomputing technology. Therefore, we always try to challenge HPCBOX and our HPC capabilities, and in the case of NDv4, we used not one but multiple instances to use them at a massive scale and exercise all the GPUs and InfiniBand links at max throughput. It was an amazing experience.
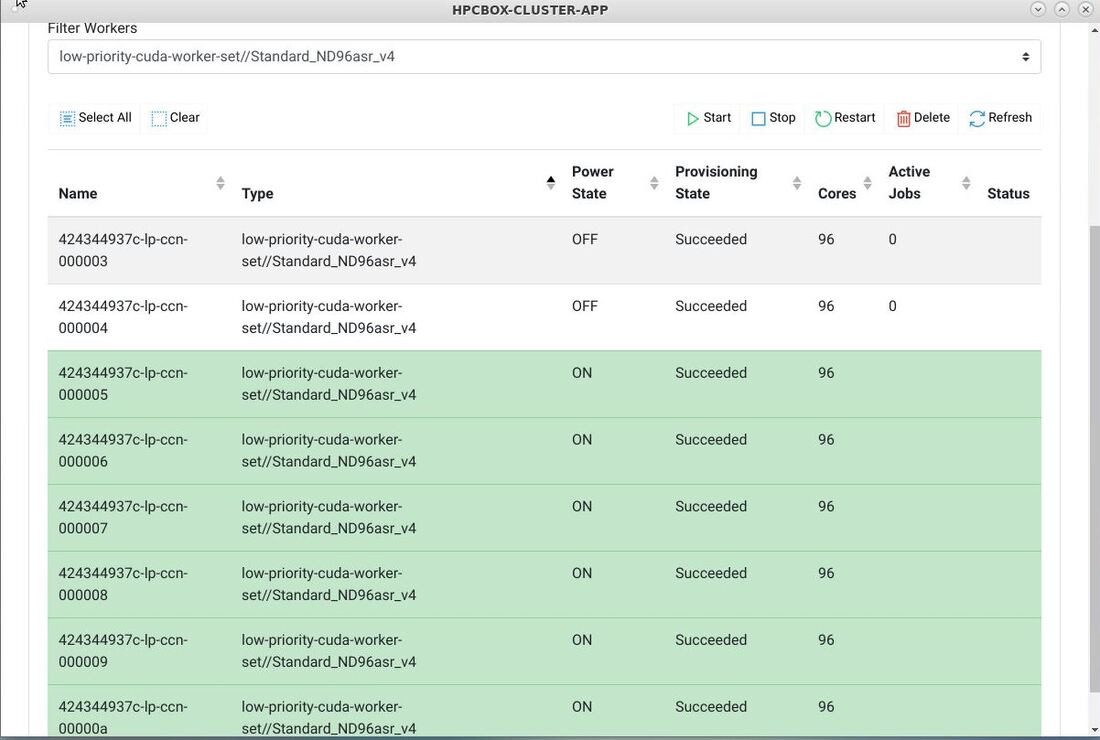
In this screenshot we see multiple NDv4 instances attached to the HPCBOX cluster and ready for use. 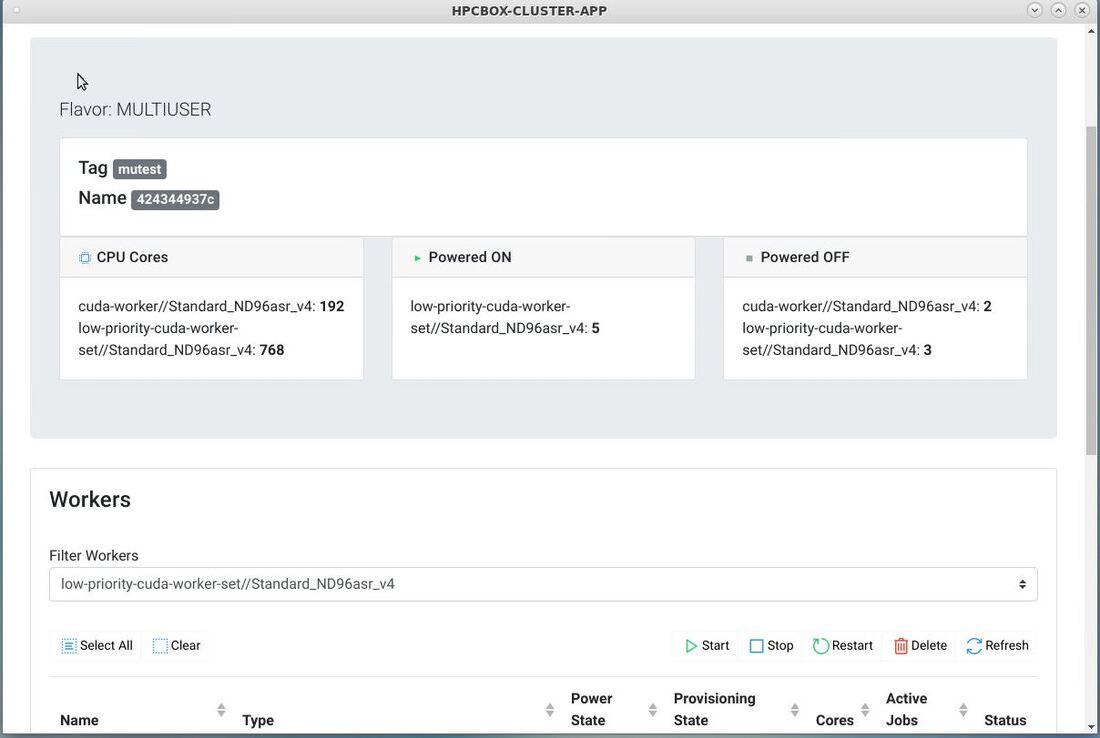
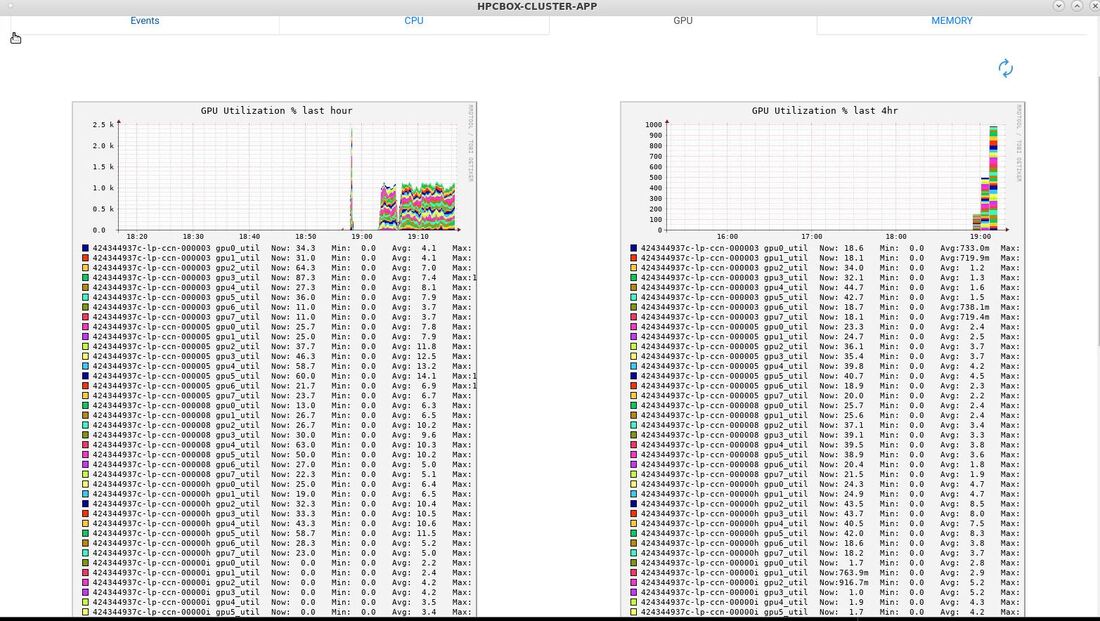
In the screenshot below, you can see some of the HPCBOX Monitoring charts showing GPU utilization (32 GPUs in this case).
.The output below shows a device-device bandwidth test across two nodes over InfiniBand.
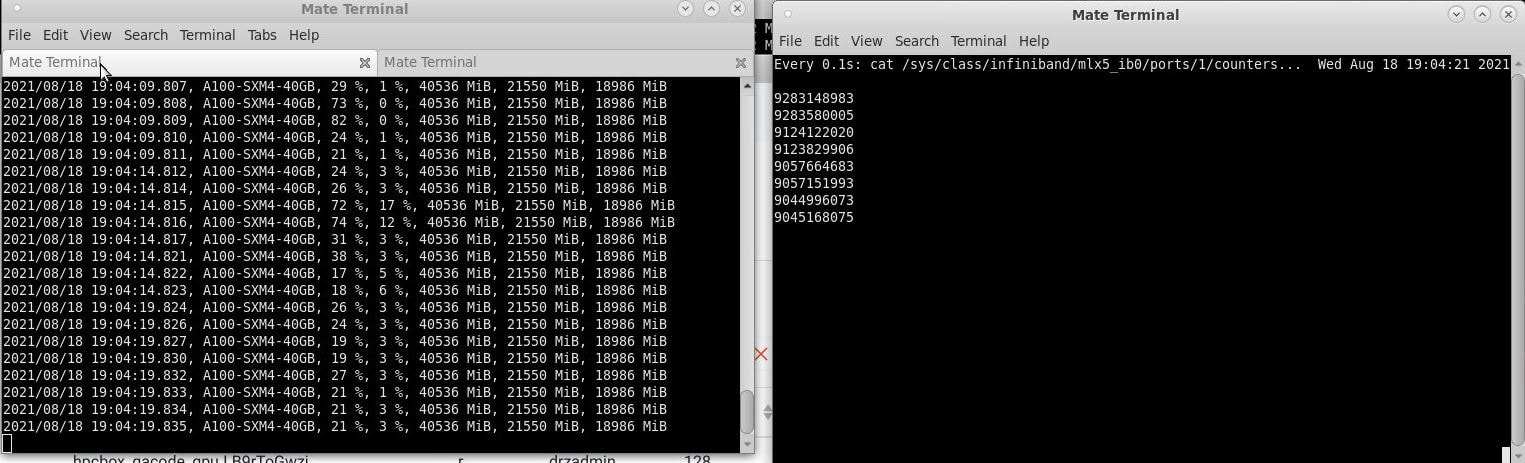
In the screenshot below, you can see a snapshot of the IB links and the GPU utilization from a four node test run.
HPCBOX AutoScaler to optimize budget spend
We recently announced support for low-priority spot priced instances in HPCBOX AutoScaler. Combining the NDv4 instances with the HPCBOX AutoScaler is a nice way to optimize your budget spend when running non-critical jobs where you can afford to have the job rescheduled and restarted when nodes get pre-empted. The nice thing about HPCBOX is that one can have both standard and low-priority instances on the same cluster and users can target different class of machines based on the importance of the jobs that they are submitting.
More to come
This post highlights how easy it is to access and use an extreme scale HPC cluster with the fully interactive user experience delivered by HPCBOX. Furthermore, with the personalized HPC support delivered by Drizti, HPC is way easier to use effectively than what it used to be and that is why we call this Personal Supercomputing!
Over time, we will be performing further tests, analysis, optimizations and try different applications on the NDv4s. Hopefully, we will be able to share some of those experiences in a future post. Availability
Get in touch with us to use HPCBOX and accelerate your innovation with extreme scale Personal Supercomputing!
Contact Us 
Author
Dev S. Founder and CTO, Drizti Inc All third-party product and company names are trademarks or registered trademarks of their respective holders. Use of them does not imply any affiliation or endorsement by them.
This post is an update to the previous post announcing preview availability of the HPCBOX AutoScaler.
Low Priority Instances
As of 2021-08-17, the HPCBOX AutoScaler includes support for low priority instances. Low priority instances are called by different names on different cloud platforms, spot instance on Azure and AWS, preemptible instance on Oracle OCI.
The general idea being, these instances are the same hardware configuration as the standard instances, but, they can be preempted at any time with a short notification by the cloud vendor. Although these instances can be evicted, they do offer a much lower price and are well suited for jobs which don't have a tight deadline. Ideal Setup
An important functionality for efficient use of low-priority instances is auto-selection and auto-rescheduling. Auto-Selection meaning, we want the right low-priority hardware to be selected based on the job type, for example, we would like to use specific GPGPU nodes for CUDA jobs, dense CPU nodes with high speed interconnect for CFD jobs, etc. Auto-rescheduling means, we would like the system to be able to automatically reschedule jobs when the cloud vendor is about to evict the instances and for applications which support it, we would also like the jobs to be automatically restarted from the last save point.
We are pleased to announce that the HPCBOX AutoScaler supports both these critical functions out of the box. Example Scenario
Let us consider a use-case to understand how the Intelligent AutoScaler in HPCBOX handles optimization and efficiently handles combining three different classes of hardware on the same cluster.
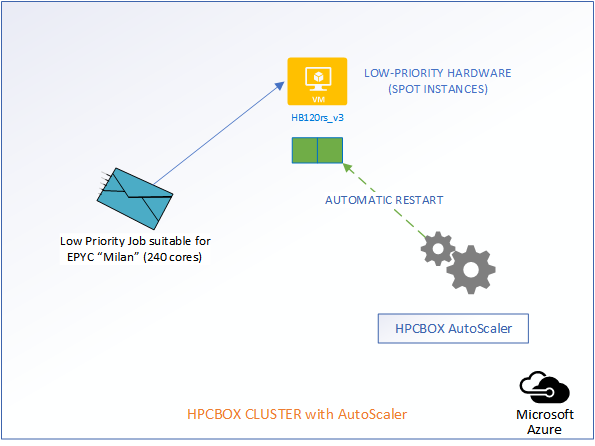
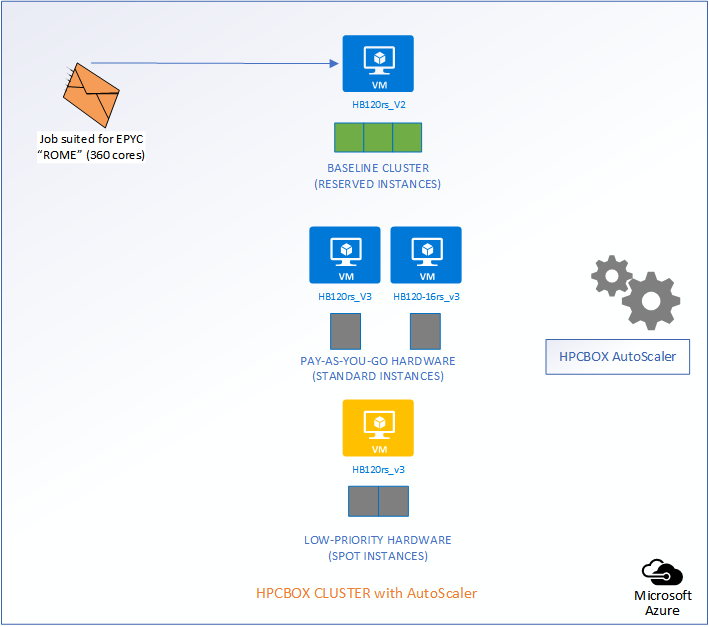
The following picture represents an HPCBOX Cluster which is a combination of both reserved (resources with a usage commitment, on Azure called Reserved Instances), standard pay-as-you-go resources and low-priority resources. To optimize the budget spend in such a configuration, one would want the reserved instances to be always powered-on to provide a baseline capacity for the cluster and automate the use of pay-as-you-go+low-priority resources to minimize resource wastage. Furthermore, we could assume that the compute workers on this cluster are a combination of different hardware configurations, for example, on Azure, we could assume a combination of HB120rs_V2 and HB120-16rs_v3 (combination of AMD EPYC “Rome” and “Milan” hardware). 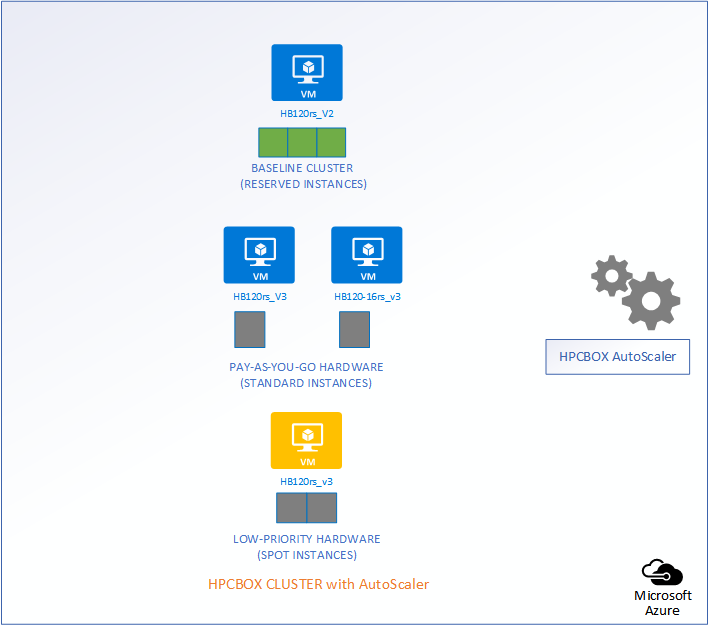
Depending on the type of job that comes into the system, AutoScaler either takes no action, powers on standard rate PAYG hardware, or, low-priority PAYG hardware. It also handles auto power-off of the instances once jobs leave the cluster.
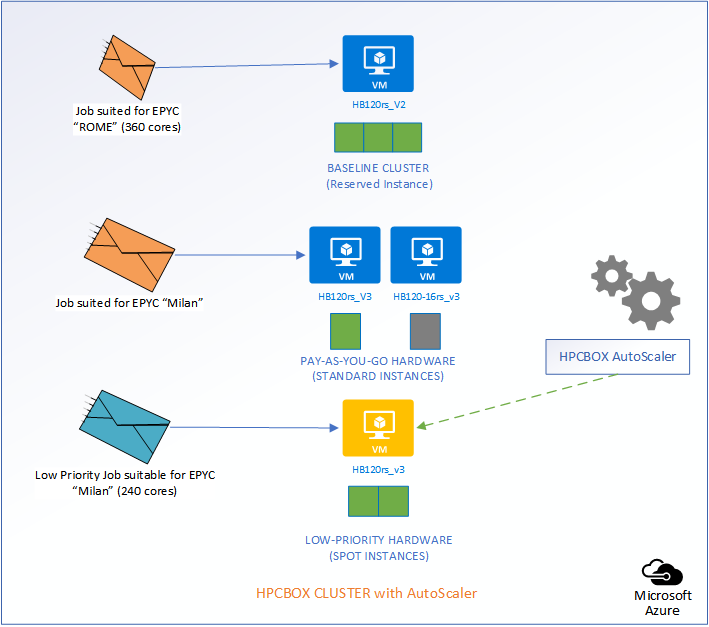
Auto-Rescheduling
When the cloud backbone decides that it needs additional hardware for users who are willing to pay more, our low-priority workers are going to get evicted. However, the AutoScaler makes sure that user jobs get automatically rescheduled without any manual intervention.
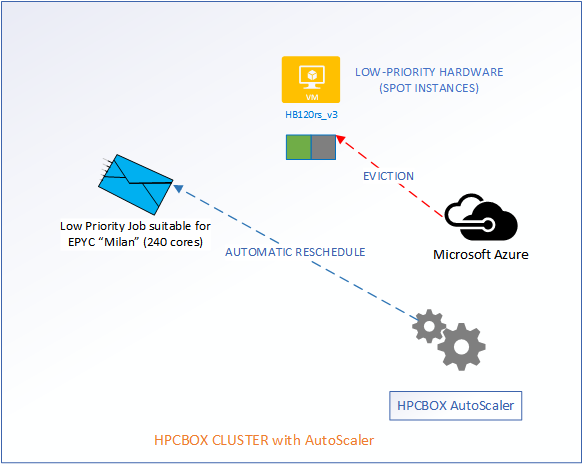
Now, comes the best part of the AutoScaler. HPCBOX can automatically attempt restarting of the evicted nodes and when successful, user jobs which got evicted will automatically restart! All this is done with no manual intervention and this, we think, is really how an Intelligent HPC Cloud system should help users optimize their resource usage, deadlines and budgets!
Availability
HPCBOX AutoScaler is now available in preview and we would be very pleased to run a demo or perform a POC or pilot with you to optimize your cloud spend on HPC resources while making sure your jobs are always matched to the most suitable hardware. Schedule a meeting here.
Author Dev S. Founder and CTO, Drizti Inc All third-party product and company names are trademarks or registered trademarks of their respective holders. Use of them does not imply any affiliation or endorsement by them.
A cool new Auto-Scaling feature is now available in preview on HPCBOX. The Intelligent AutoScaler, built into the HPCBOX platform, automatically starts required number of Compute, GPU and CUDA workers suitable for a particular user job. Furthermore, the AutoScaler can automatically identify idle workers and power them off when there are no user jobs waiting to be executed on the HPCBOX cluster.
The HPCBOX AutoScaler is designed to require almost zero configuration from the administrator for taking advantage of auto scaling (no configuration required with set up of special host groups, scale sets etc.) and be cloud vendor agnostic, meaning, when HPCBOX is available on other cloud platforms like AWS or GCP, autoscaling should work the same way as it does on Microsoft Azure which is the current preferred platform for HPCBOX. Why AutoScaling?
HPCBOX has two modes of operation, a cluster can either be used for Personal Supercomputing, meaning, a cluster is for dedicated use of one user, or, a cluster can be in a Multi-User configuration which is more of a traditional set up with multiple users sharing a cluster, running different applications, distributed parallel, GPU accelerated and those that are used for visualization on workers which have a OpenGL capable GPU.
Dedicated single user clusters do not generally require any kind of autoscaling functionality because a user operates it like their PC/laptop and has complete control over its operation. Multi-User setups, however, can involve more complexity, especially when:
Example Scenario
Let us use a use-case to understand how the Intelligent AutoScaler in HPCBOX handles optimization of resources and budgets on the cluster.
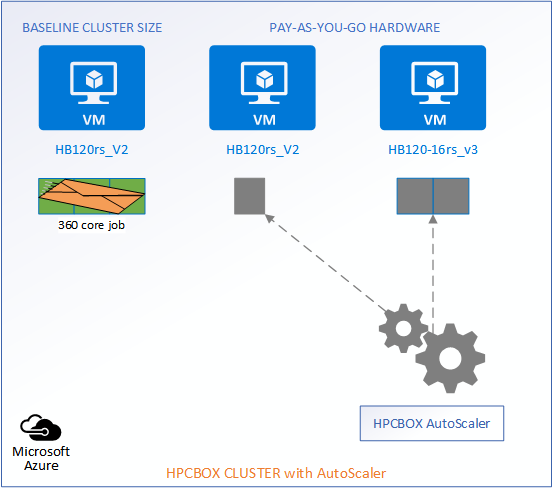
The following picture represents an HPCBOX Cluster which is a combination of both reserved (resources with a usage commitment, on Azure called Reserved Instances) and pay-as-you-go resources. To optimize the budget spend in such a configuration, one would want the reserved instances to be always powered-on to provide a baseline capacity for the cluster and automate the use of pay-as-you-go resources to minimize resource wastage. Furthermore, we could assume that the compute workers on this cluster are a combination of different hardware configurations, for example, on Azure, we could assume a combination of HB120rs_V2 and HB120-16rs_v3 (combination of AMD EPYC “Rome” and “Milan” hardware). 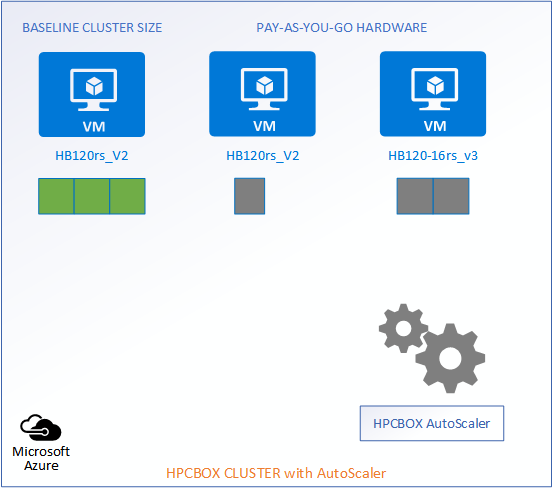
Reserved Instances -> 3 HB120rs_V2
Pay-as-you-go -> 1 HB120rs_V2 and 2 HB120-16rs_v3
When a job which can be satisfied by the baseline resources comes into the system, the AutoScaler does nothing and lets the job get scheduled on the available compute workers.
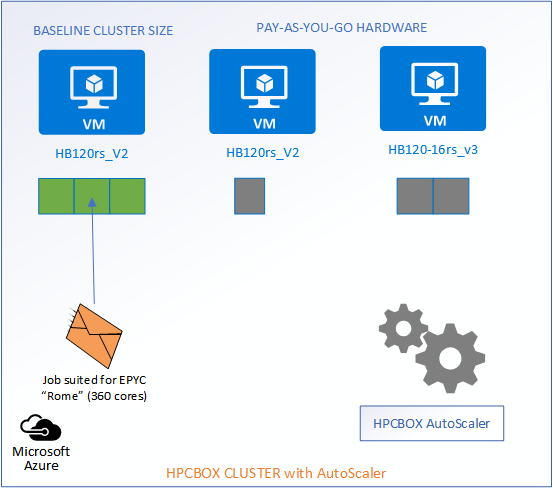
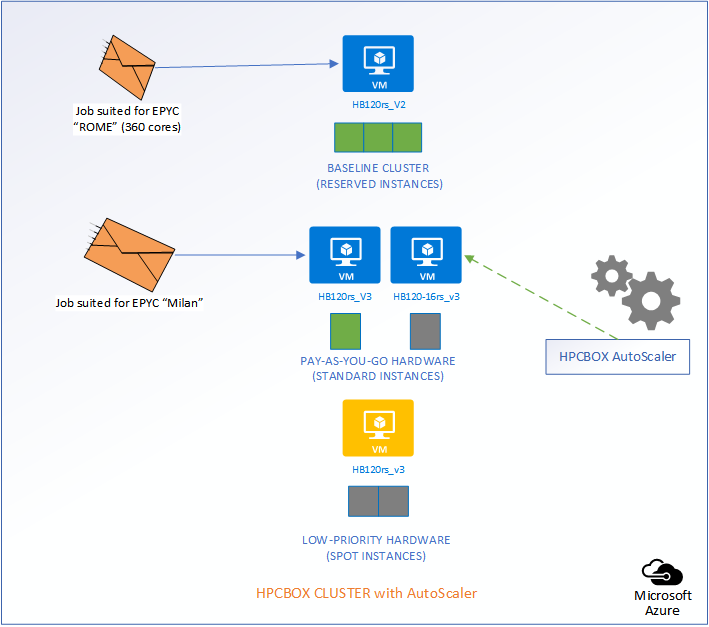
When new jobs come into the system, the AutoScaler gets into action and matches the jobs to the most suitable hardware, intelligently calculates the required number of workers which would satisfy the job and powers them on with no admin/user interaction. For example, we see in the image below that two jobs have entered the system, each suitable for different hardware configurations, AMD Epyc “Rome” powered HB120rs_V2 and AMD Epyc “Milan” powered 16 core HB120-16rs_v3.
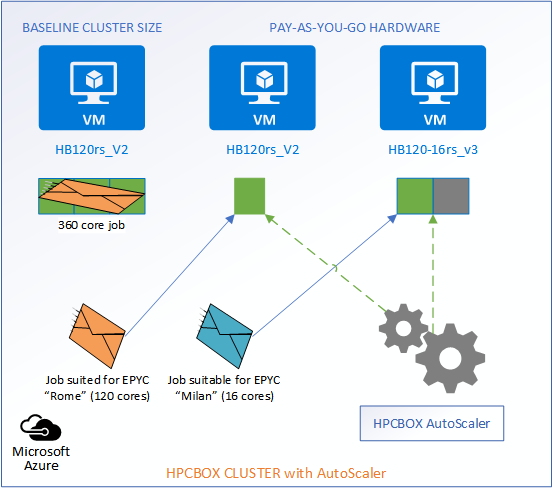
When jobs exit the system, the AutoScaler automatically identifies the idle workers and powers them off while maintaining the baseline configuration of the cluster.
Visual Monitoring
Visualization is important for users to know when their jobs might start. HPCBOX includes a new AutoScaler event monitoring stream which automatically gets updated with every action the AutoScaler is currently taking and will be taking in the next iterations.
Availability
HPCBOX AutoScaler is now available in preview and we would be very pleased to run a demo or perform a POC or pilot with you to optimize your cloud spend on HPC resources while making sure your jobs are always matched to the most suitable hardware. Schedule a meeting here. 
Author Dev S. Founder and CTO, Drizti Inc All third-party product and company names are trademarks or registered trademarks of their respective holders. Use of them does not imply any affiliation or endorsement by them. |
 RSS Feed
RSS Feed