
IntroductionWe are excited to announce support for Convergent Science products on the HPCBOX™, HPC Cloud Platform. This article details the capabilities and the benefits provided by the HPCBOX Platform for CONVERGE users. CONVERGECONVERGE is a cutting-edge CFD software package that eliminates all user meshing time through fully autonomous meshing. CONVERGE automatically generates a perfectly orthogonal, structured grid at runtime based on simple, user-defined grid control parameters. Thanks to its fully coupled automated meshing and its Adaptive Mesh Refinement (AMR) technology, CONVERGE can easily analyze complex geometries, including those with moving boundaries. Moreover, CONVERGE contains an efficient detailed chemistry solver, an extensive set of physical submodels, a genetic algorithm optimization module, and fully automated parallelization. HPCBOXHPCBOX delivers an innovative desktop-centric workflow enabled platform for users who want to accelerate innovation using cutting edge technologies that can benefit from High Performance Computing Infrastructure. It aims to make supercomputing technology accessible and easier for scientists, engineers and other innovators who do not have access to in-house datacenters or skills to create, manage and maintain complex HPC infrastructure. To achieve a high level of simplicity in delivering a productive HPC platform, HPCBOX leverages unique technology that not only allows users to create workflows combining their applications and optimization of underlying infrastructure into the same pipeline, but also provides integration points to help third-party applications directly hook into its infrastructure optimization capability. Some of the unique capabilities of HPCBOX are:
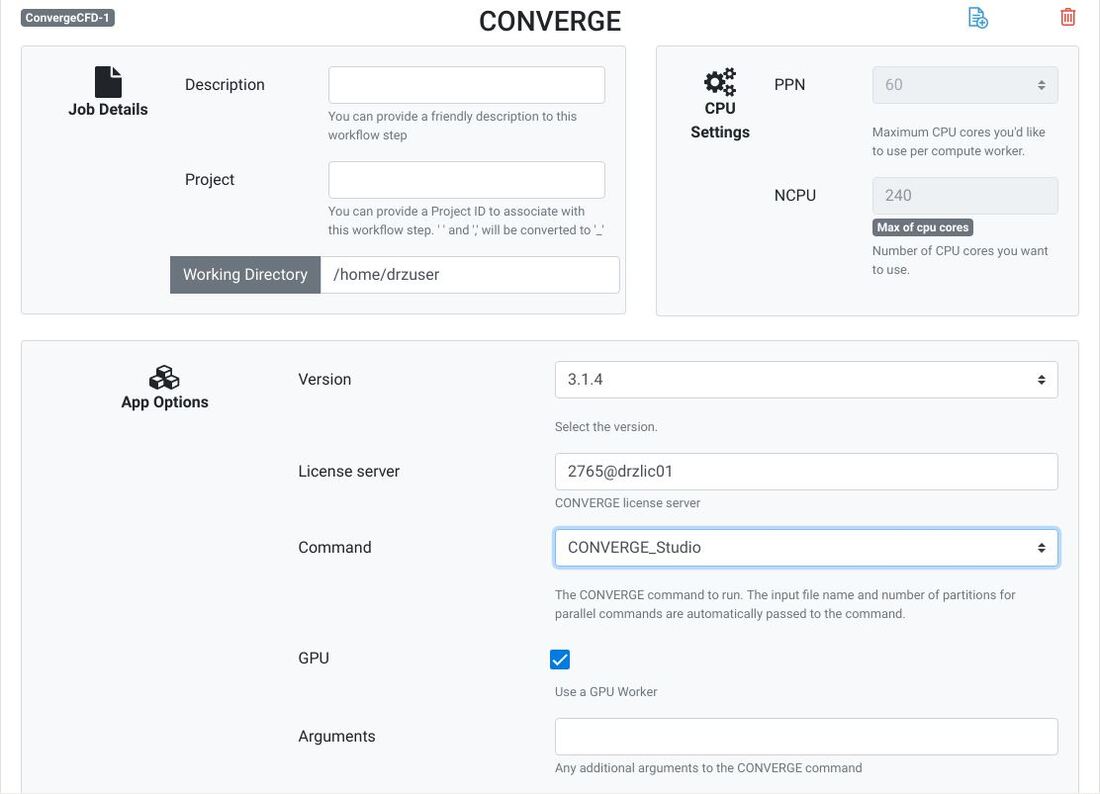
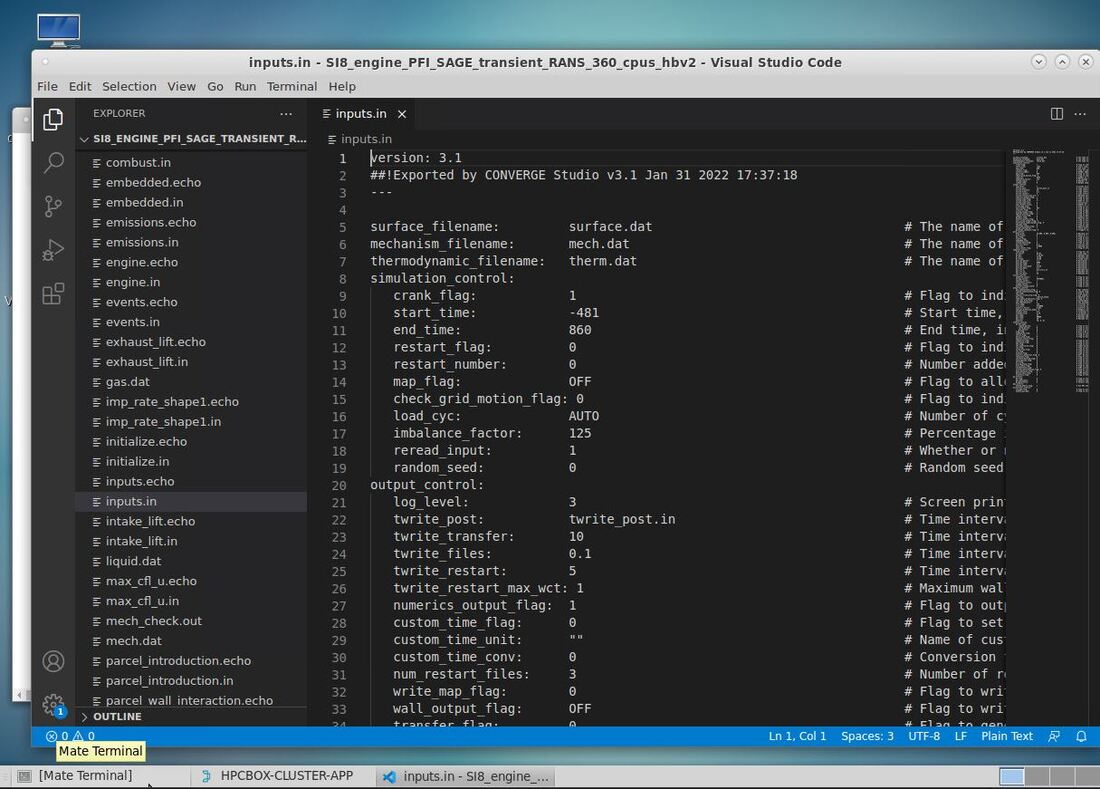
CONVERGE support in HPCBOXHPCBOX provides end to end support for the entire user workflow for CONVERGE with its fully interactive user experience capabilities and empowers CONVERGE users with the possibility to perform their entire pre/solve and post processing directly on an HPCBOX cluster. HPCBOX clusters for CONVERGE are optimized for delivering the best possible performance available on the cloud, utilizing Microsoft Azure’s Milan-X based HBv3 instance types for solving and NV instances with OpenGL capable NVIDIA graphics cards for optimal user experience when using CONVERGE Studio and Tecplot for CONVERGE. HPCBOX also sets up the most suitable MPI and networking configuration, specifically HPC-X for delivering the best possible performance when users are executing large scale models which span across multiple compute nodes which are interconnected with Azure’s state-of-art InfiniBand HDR network. Using CONVERGE on HPCBOXUsers can create application pipelines seamlessly by using HPCBOX’s CONVERGE application. HPCBOX automatically proposes the most suitable configuration for every step in the workflow. For example, selecting CONVERGE_Studio will automatically trigger use of a graphics node which is powered by an OpenGL capable NVIDIA graphics card. Furthermore, depending on the model, users have an option to set the number of MPI tasks on each compute node involved in the computation. This allows for optimal configuration with the required amount of memory for each cpu core involved in the MPI communication. With the fully interactive user experience delivered by HPCBOX, CONVERGE users can easily edit their input files directly on the cluster and work the same way as they would on their local workstations or laptops. The entire HPC optimization is handled automatically by HPCBOX reducing the learning curve for users who don’t have much experience with HPC clusters. 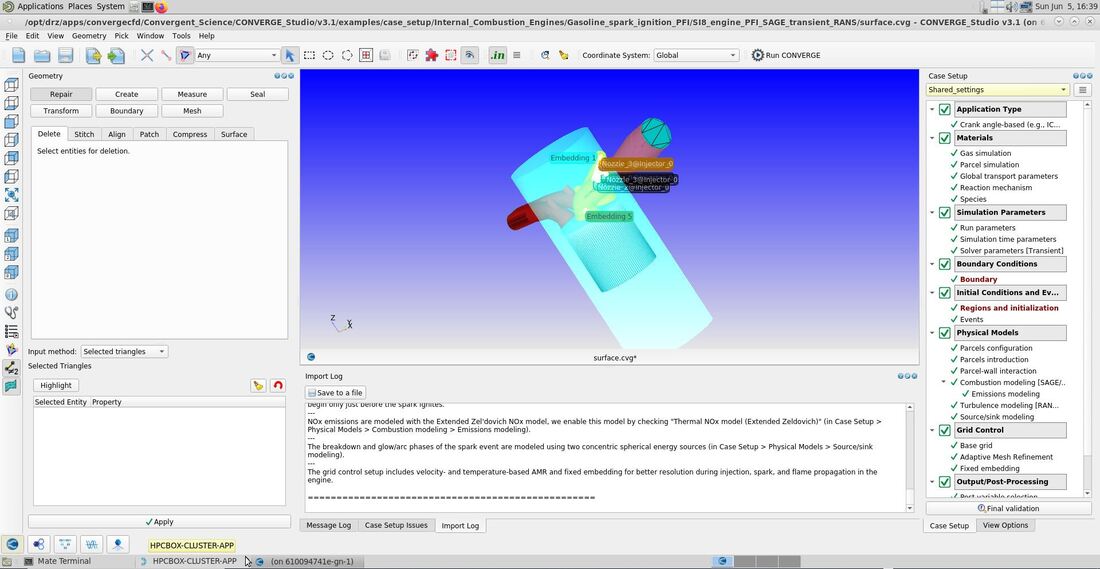 Fully interactive user experience for CONVERGE_Studio Users will also be able to track the progress of their simulation in real time within the HPCBOX environment. Additionally, using the connect/disconnect feature of HPCBOX, users can start a simulation on the cluster from one location, and connect from anywhere else to follow up on it. Convergent Science support personnel will be able to connect to the user’s desktop on the HPCBOX cluster and provide real time support when required. This eliminates the need to transfer model files back and forth between the user and the support team and improve the support experience. Get StartedTo get started with using HPC on Azure for your Convergent Science products get in touch with HPCBOX support to discuss further. Please use this Contact Form to get in touch! About Convergent ScienceConvergent Science (www.convergecfd.com) is an innovative, rapidly expanding computational fluid dynamics (CFD) company. Our flagship product, CONVERGE CFD software, eliminates the grid generation bottleneck from the simulation process. Founded in 1997 by graduate students at the University of Wisconsin-Madison, Convergent Science was a CFD consulting company in its early years. In 2008, the first CONVERGE licenses were sold and the company transitioned to a CFD software company. Convergent Science remains headquartered in Madison, Wisconsin, with offices in the United States, Europe, and India and distributors around the globe. About Drizti Inc.Toronto, Canada based Drizti (www.drizti.com) delivers Personal Supercomputing. We believe, access, and use of a supercomputer should be as straightforward as using a personal computer. We’ve set out to upgrade the supercomputing experience for users with our expertise of High Performance Computing(HPC), High Throughput Computing, distributed system architecture and HPC cloud design. We aim to make scalable computing accessible to every innovator, helping them compete and innovate with the same freedom they enjoy on their personal workstations and laptops. Drizti’s HPCBOX platform delivers the same rich desktop experience they are used to when building complex products and applications locally and empowers them with workflow capabilities to streamline their application pipelines and automatically optimizes the underlying HPC infrastructure for every step in the workflow.  Author Dev S. Founder and CTO, Drizti Inc
This post is short since it's an update to a previous post which can be found here.
Early Holiday Gift
On November 8th, 2021, Microsoft delivered an early Holiday Gift by announcing the preview availability of an upgraded version of the Azure HBv3 virtual machines. This upgraded instance was enhanced by 3rd Gen AMD EPYC™ processors with AMD 3D V-cache, codenamed “Milan-X”.
Being a Microsoft Partner, and always staying at the forefront of HPC in the cloud, delivering one of the easiest to use and scale HPC cloud platforms, HPCBOX, we at Drizti, had to get our hands on this new hardware and make sure our HPCBOX platform was able to support it immediately on GA. So, obviously, we signed up for the private preview and Microsoft was kind enough to get us access around late November/early December. Technical Specification
I won't be going into much detail of the technical specification for the upgraded SKU since a lot of information and initial benchmark results have been provided on this Azure Blog and this Microsoft Tech Community article. In short, this upgraded SKU has the same InfiniBand capability as the original HBv3 i.e., HDR, same amount of 448GB memory and local scratch nVME. However, the main change is the switch to AMD EPYC™ processors with AMD 3D V-cache, codenamed “Milan-X” which offers a significant boost to L3 cache and brings it to around 1.5 gigabytes on a dual socket HBv3 instance.
Tests and Amazing Results
We performed a few tests to make sure that the HPCBOX platform was ready to support this upgraded SKU once it was released. We highlight the tests and the execution time speedup we noticed for them. I am not including case names and details here because some of them are customer model files. However, if you would like to get more details feel free to contact us.
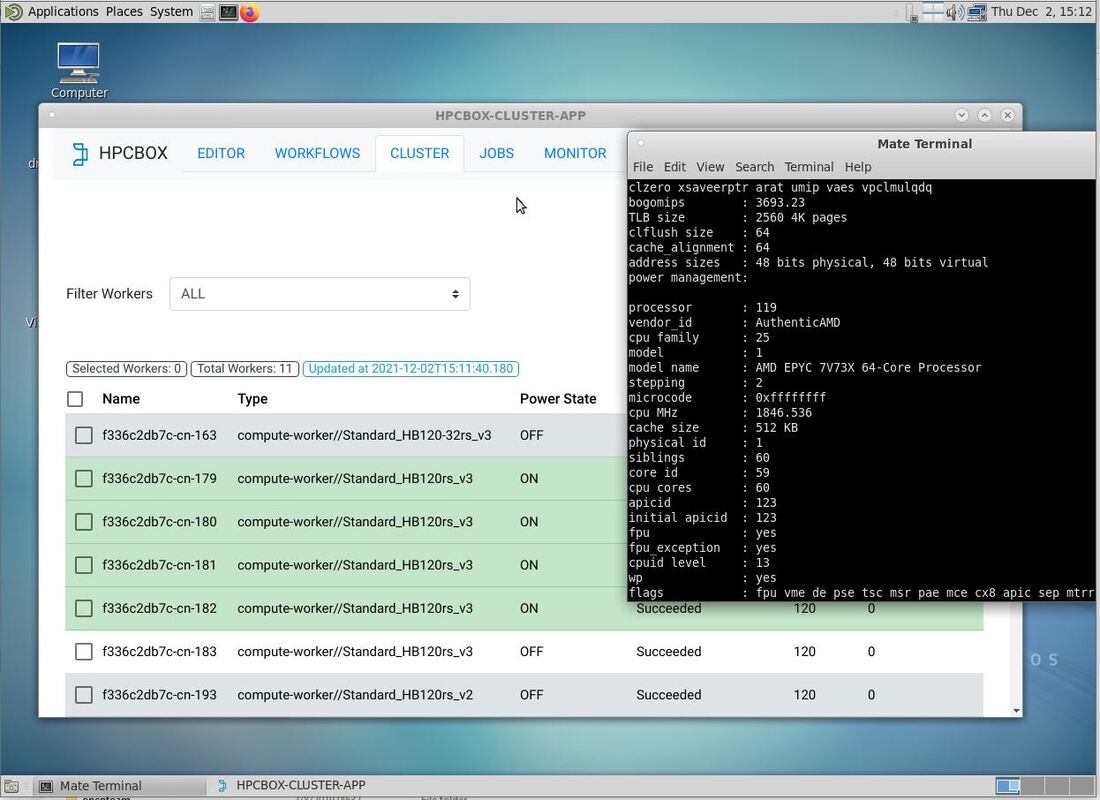
In the above screenshot, you can see 4 powered-on HBv3 compute workers on an HPCBOX cluster. These HBv3 instances are the upgraded version of the SKU and on the right you can see the CPU information.
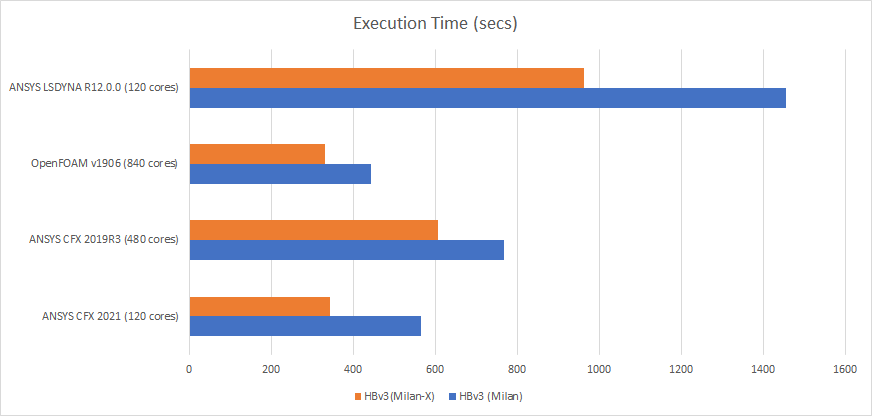
Lower is better
The tests were run on an HPCBOX cluster using CentOS 7.X as the base image.
In the chart and table above, we can clearly see a good improvement in performance using Milan-X. The larger cache size seems to give a good boost for the applications we tested and it appears that this boost will most likely be experienced with other workloads as well.
Availability in HPCBOX
Being at the forefront of HPC in the cloud, specifically on Microsoft Azure, Drizti is ready for the GA release of the upgraded HBv3 instances and we will be continuing our tests and providing feedback to Microsoft. We have a few more tests to conduct and also to make sure our AutoScaler is able to perform as expected with the Milan-X instances. It appears that the new HBv3 will be a drop in replacement in HPCBOX and most likely will just work out of the box with all the functionality delivered by HPCBOX.
Conclusion
Microsoft Azure has been the leader in delivering cutting-edge infrastructure for HPC in the cloud and we are privileged to have been partnering with the Azure HPC team. We had the opportunity of not only being a launch part for the original HBv3 "Milan" instances, but now, also be one of the early partners to test compatibility of these upgraded SKUs with Milan-X. AMD EPYC "Milan" was a big upgrade for HPC and with Milan-X, it appears that AMD has advanced further and delivered another cutting-edge CPU with amazing performance. Drizti, with our HPCBOX platform on Microsoft Azure is able to deliver a fully interactive Supercomputing experience for our users and it's very exciting that we can upgrade our end users and accelerate their innovation in minutes by just upgrading their compute nodes! Contact us to learn how you can get rid of in-house hardware and/or your existing cloud presence and get a seamless HPC upgrade to HPCBOX on Azure. 
Author
Dev S. Founder and CTO, Drizti Inc All third-party product and company names are trademarks or registered trademarks of their respective holders. Use of them does not imply any affiliation or endorsement by them.
This post is an update to the previous post announcing preview availability of the HPCBOX AutoScaler.
Low Priority Instances
As of 2021-08-17, the HPCBOX AutoScaler includes support for low priority instances. Low priority instances are called by different names on different cloud platforms, spot instance on Azure and AWS, preemptible instance on Oracle OCI.
The general idea being, these instances are the same hardware configuration as the standard instances, but, they can be preempted at any time with a short notification by the cloud vendor. Although these instances can be evicted, they do offer a much lower price and are well suited for jobs which don't have a tight deadline. Ideal Setup
An important functionality for efficient use of low-priority instances is auto-selection and auto-rescheduling. Auto-Selection meaning, we want the right low-priority hardware to be selected based on the job type, for example, we would like to use specific GPGPU nodes for CUDA jobs, dense CPU nodes with high speed interconnect for CFD jobs, etc. Auto-rescheduling means, we would like the system to be able to automatically reschedule jobs when the cloud vendor is about to evict the instances and for applications which support it, we would also like the jobs to be automatically restarted from the last save point.
We are pleased to announce that the HPCBOX AutoScaler supports both these critical functions out of the box. Example Scenario
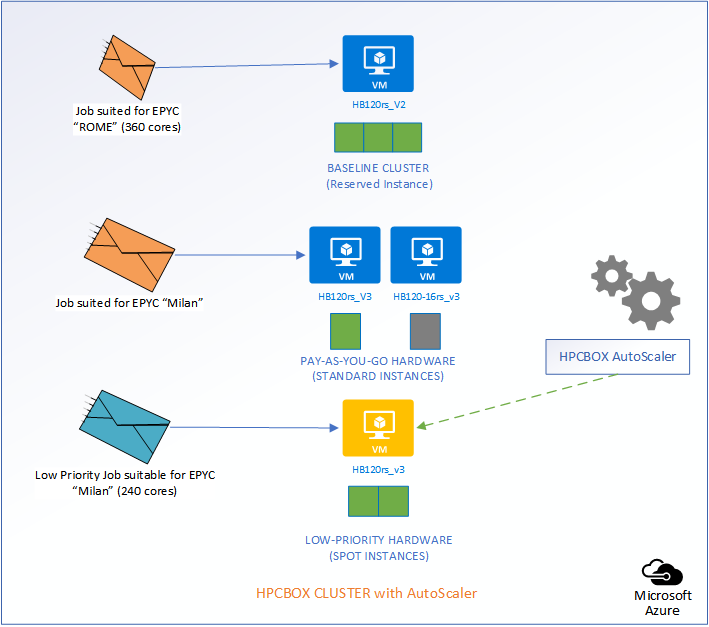
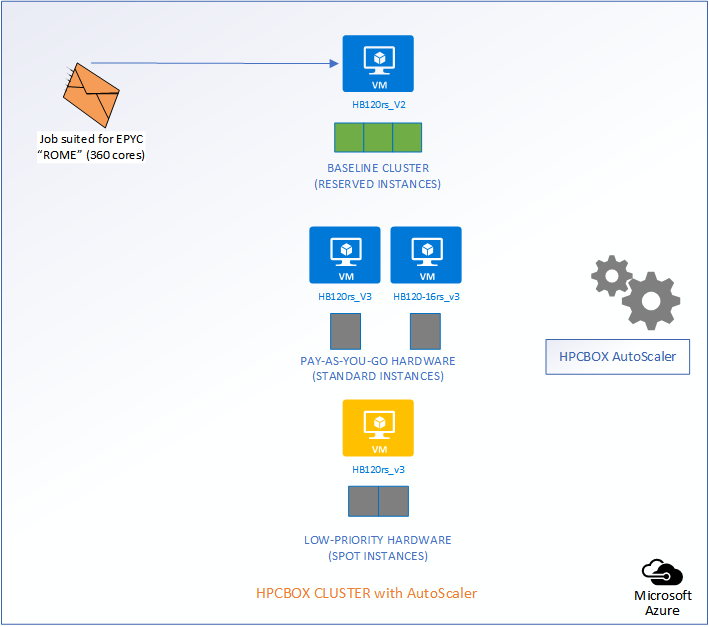
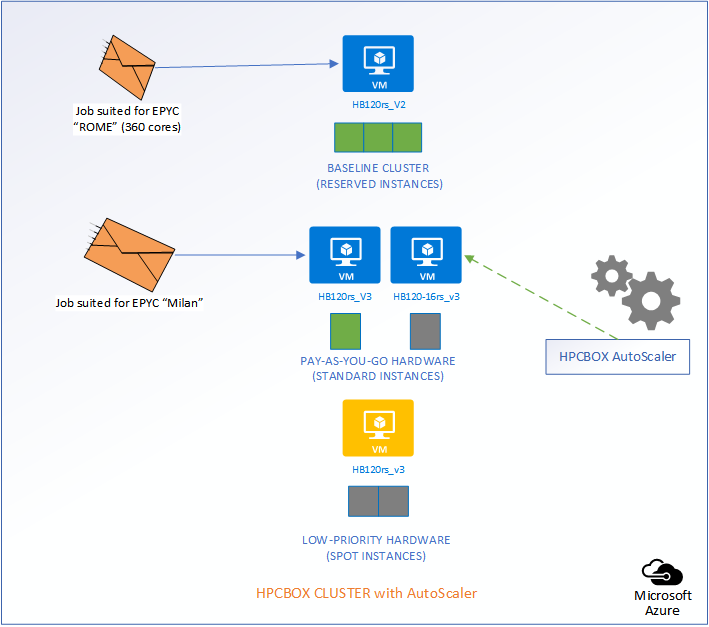
Let us consider a use-case to understand how the Intelligent AutoScaler in HPCBOX handles optimization and efficiently handles combining three different classes of hardware on the same cluster.
The following picture represents an HPCBOX Cluster which is a combination of both reserved (resources with a usage commitment, on Azure called Reserved Instances), standard pay-as-you-go resources and low-priority resources. To optimize the budget spend in such a configuration, one would want the reserved instances to be always powered-on to provide a baseline capacity for the cluster and automate the use of pay-as-you-go+low-priority resources to minimize resource wastage. Furthermore, we could assume that the compute workers on this cluster are a combination of different hardware configurations, for example, on Azure, we could assume a combination of HB120rs_V2 and HB120-16rs_v3 (combination of AMD EPYC “Rome” and “Milan” hardware). 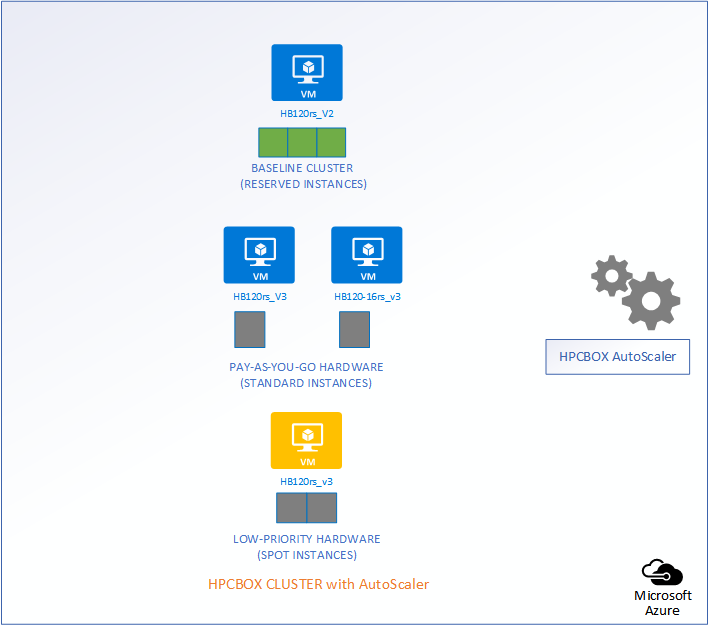
Depending on the type of job that comes into the system, AutoScaler either takes no action, powers on standard rate PAYG hardware, or, low-priority PAYG hardware. It also handles auto power-off of the instances once jobs leave the cluster.
Auto-Rescheduling
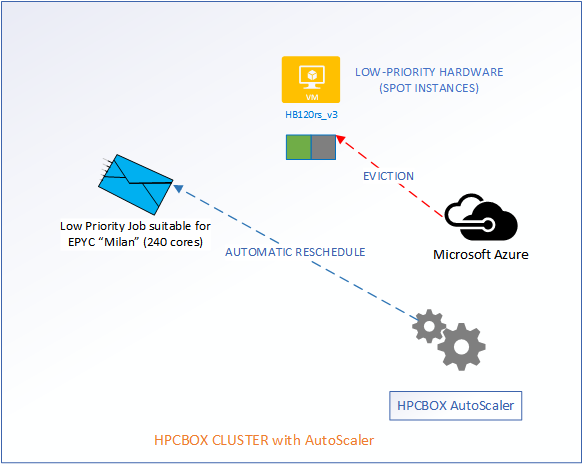
When the cloud backbone decides that it needs additional hardware for users who are willing to pay more, our low-priority workers are going to get evicted. However, the AutoScaler makes sure that user jobs get automatically rescheduled without any manual intervention.
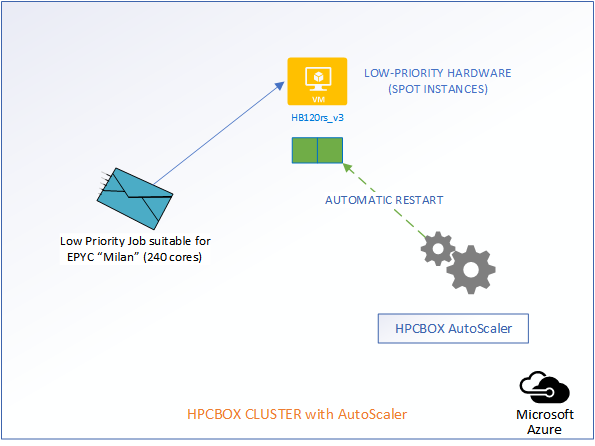
Now, comes the best part of the AutoScaler. HPCBOX can automatically attempt restarting of the evicted nodes and when successful, user jobs which got evicted will automatically restart! All this is done with no manual intervention and this, we think, is really how an Intelligent HPC Cloud system should help users optimize their resource usage, deadlines and budgets!
Availability
HPCBOX AutoScaler is now available in preview and we would be very pleased to run a demo or perform a POC or pilot with you to optimize your cloud spend on HPC resources while making sure your jobs are always matched to the most suitable hardware. Schedule a meeting here.
Author Dev S. Founder and CTO, Drizti Inc All third-party product and company names are trademarks or registered trademarks of their respective holders. Use of them does not imply any affiliation or endorsement by them.
A cool new Auto-Scaling feature is now available in preview on HPCBOX. The Intelligent AutoScaler, built into the HPCBOX platform, automatically starts required number of Compute, GPU and CUDA workers suitable for a particular user job. Furthermore, the AutoScaler can automatically identify idle workers and power them off when there are no user jobs waiting to be executed on the HPCBOX cluster.
The HPCBOX AutoScaler is designed to require almost zero configuration from the administrator for taking advantage of auto scaling (no configuration required with set up of special host groups, scale sets etc.) and be cloud vendor agnostic, meaning, when HPCBOX is available on other cloud platforms like AWS or GCP, autoscaling should work the same way as it does on Microsoft Azure which is the current preferred platform for HPCBOX. Why AutoScaling?
HPCBOX has two modes of operation, a cluster can either be used for Personal Supercomputing, meaning, a cluster is for dedicated use of one user, or, a cluster can be in a Multi-User configuration which is more of a traditional set up with multiple users sharing a cluster, running different applications, distributed parallel, GPU accelerated and those that are used for visualization on workers which have a OpenGL capable GPU.
Dedicated single user clusters do not generally require any kind of autoscaling functionality because a user operates it like their PC/laptop and has complete control over its operation. Multi-User setups, however, can involve more complexity, especially when:
Example Scenario
Let us use a use-case to understand how the Intelligent AutoScaler in HPCBOX handles optimization of resources and budgets on the cluster.
The following picture represents an HPCBOX Cluster which is a combination of both reserved (resources with a usage commitment, on Azure called Reserved Instances) and pay-as-you-go resources. To optimize the budget spend in such a configuration, one would want the reserved instances to be always powered-on to provide a baseline capacity for the cluster and automate the use of pay-as-you-go resources to minimize resource wastage. Furthermore, we could assume that the compute workers on this cluster are a combination of different hardware configurations, for example, on Azure, we could assume a combination of HB120rs_V2 and HB120-16rs_v3 (combination of AMD EPYC “Rome” and “Milan” hardware). 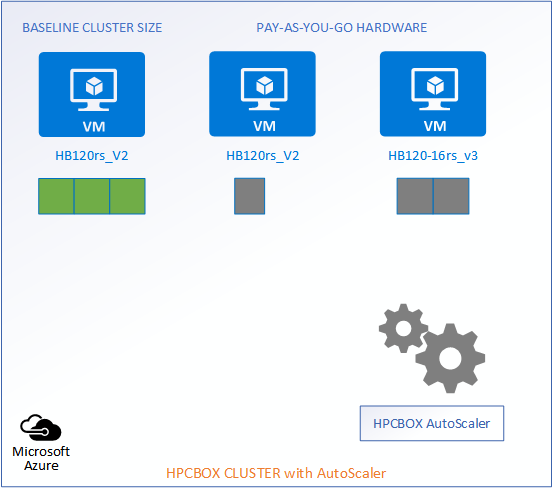
Reserved Instances -> 3 HB120rs_V2
Pay-as-you-go -> 1 HB120rs_V2 and 2 HB120-16rs_v3
When a job which can be satisfied by the baseline resources comes into the system, the AutoScaler does nothing and lets the job get scheduled on the available compute workers.
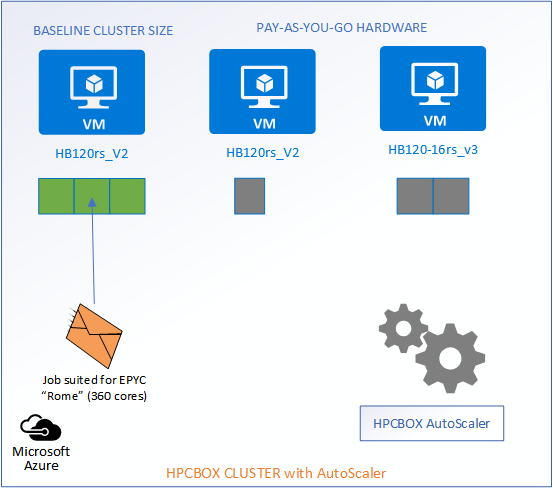
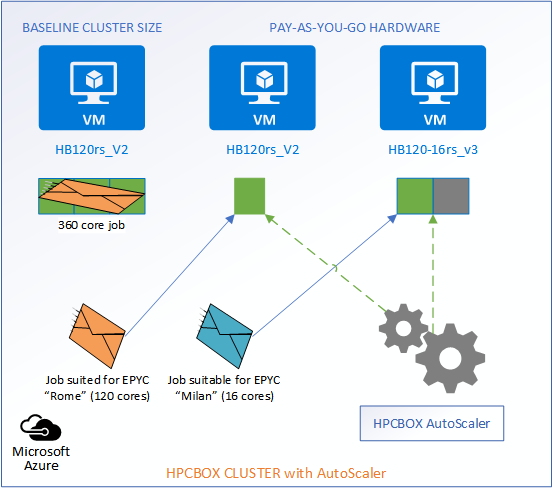
When new jobs come into the system, the AutoScaler gets into action and matches the jobs to the most suitable hardware, intelligently calculates the required number of workers which would satisfy the job and powers them on with no admin/user interaction. For example, we see in the image below that two jobs have entered the system, each suitable for different hardware configurations, AMD Epyc “Rome” powered HB120rs_V2 and AMD Epyc “Milan” powered 16 core HB120-16rs_v3.
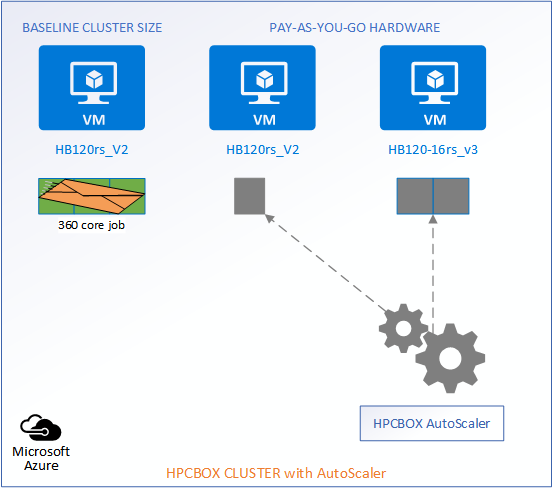
When jobs exit the system, the AutoScaler automatically identifies the idle workers and powers them off while maintaining the baseline configuration of the cluster.
Visual Monitoring
Visualization is important for users to know when their jobs might start. HPCBOX includes a new AutoScaler event monitoring stream which automatically gets updated with every action the AutoScaler is currently taking and will be taking in the next iterations.
Availability
HPCBOX AutoScaler is now available in preview and we would be very pleased to run a demo or perform a POC or pilot with you to optimize your cloud spend on HPC resources while making sure your jobs are always matched to the most suitable hardware. Schedule a meeting here. 
Author Dev S. Founder and CTO, Drizti Inc All third-party product and company names are trademarks or registered trademarks of their respective holders. Use of them does not imply any affiliation or endorsement by them.
This is one of the most exciting posts I’ve written in my 15+ years of existence in the High Performance Computing (HPC) industry.
AMD EPYC Zen 3 “Milan” is integrated, tested and available on the HPCBOX platform on Microsoft Azure, on LAUNCH DAY! This is something which seldom happens in the HPC world, very few users ever get to start production on day one of the release of a new and very impressive processor generation upgrade. I will not be doing any technical comparison between Zen 3 and Zen 2 and neither will I present any specific application benchmark numbers in this post. I am sure there’ll be many posts by AMD, Microsoft and other ISVs who’ll be publicly sharing information on the performance boost they see for their codes with EPYC Zen 3 “Milan”. This post will be more about HPCBOX and how we could deliver this upgrade experience for our users, on launch day and without having to set our hands on the physical hardware or physically be present in a datacenter(s) (actually multiple regions)! Awesome work and support from the Azure team! Drizti was a launch partner for the new HBv3 instance size on Microsoft Azure and these instances are powered by the new EPYC 7xx3/Milan CPUs, HDR InfiniBand and sport very impressive dual NVMe drives which give a big performance boost to applications which use local scratch, specifically when they are striped. Read more about HBv3 here Unbelievably quick CPU generation upgrade
It all started with Drizti getting access to 1000+ cores of HBv3 instances for functional and compatibility testing, to make sure we are ready for GA availability of HBv3 on launch day of AMD EPYC ”Milan” CPUs. We went through testing, adding necessary support within the HPCBOX platform to make sure we are able to use the cool new features available on the instances, like automate striping of NVMe, testing out MPI compatibility, testing the workflow component of HPCBOX, auto-scaling/shutdown/start etc. and all other functions which are offered by the HPCBOX platform. In addition to this, we also did some performance tests with different ISV and open-source codes, mainly to make sure the HPCBOX workflow engine can correctly handle the new instances and automatically optimize application pipelines to take advantage of the new hardware.
Some of the applications we tested were ANSYS CFX, ANSYS Fluent, OpenFOAM. At a high level, we can share that we are seeing impressive performance benefits of using EPYC “Milan”, particularly for large runs. Also, for applications which are local scratch bound, we expect users to get a good boost due to the possibility of having striped NVMes in HBv3. We also did a test to see how easy it would be to upgrade HPC for our users and were really impressed that we could just switch our users from HBv2 to HBv3, meaning from “Rome” to “Milan” and to upgraded local scratch in under 30 minutes! This is mainly because of the design of the HPCBOX platform, it is a self-contained platform, and this gives us the ability to fine tune platform capabilities quickly without depending on external services to get upgraded first. Agile and Impressive! In Action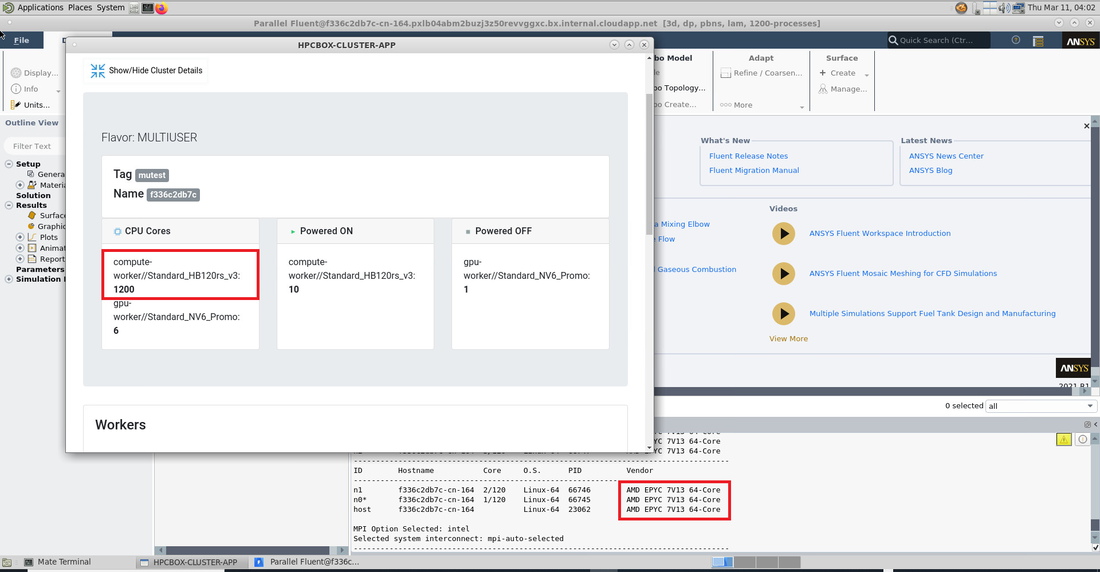
ANSYS Fluent started on HPCBOX with the new HBv3 as compute nodes
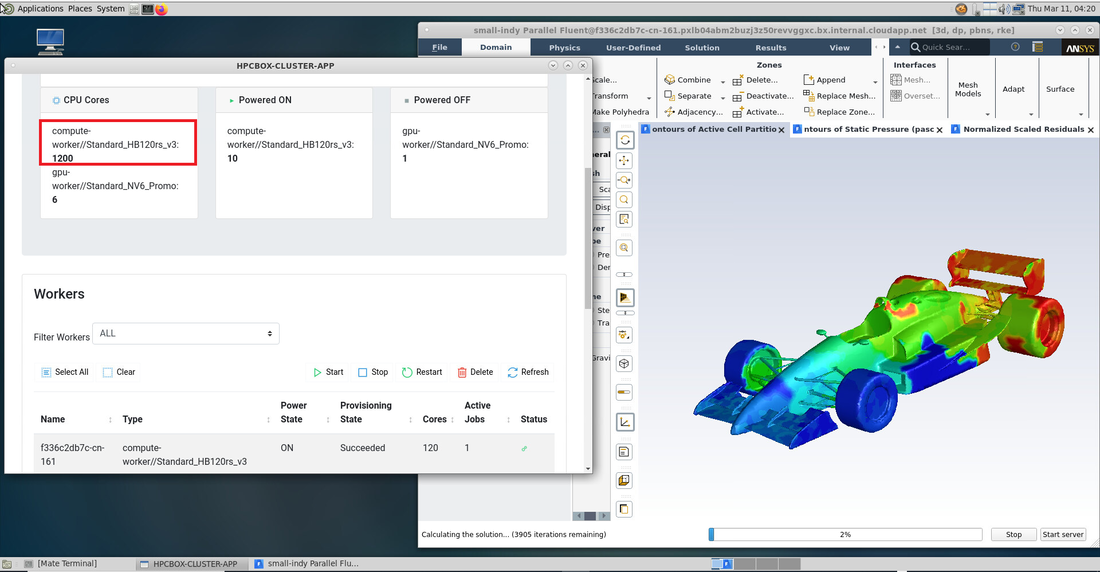
ANSYS Fluent iterating on HPCBOX using 1200 cores of HBv3
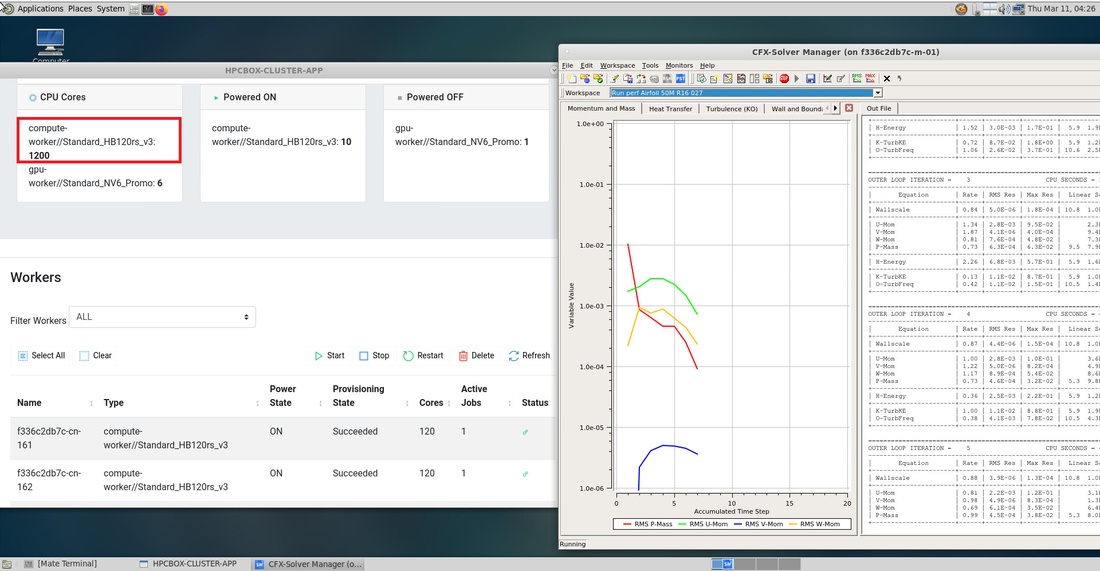
ANSYS CFX on HPCBOX powered by 1200 HBv3 cores
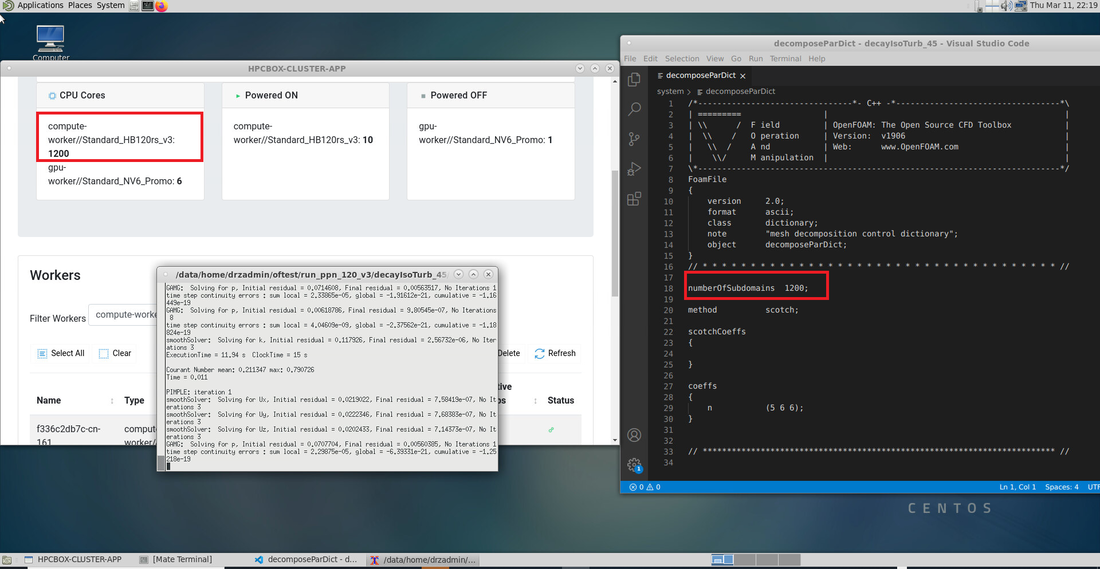
OpenFOAM on HPCBOX utilizing 1200 HBv3 AMD EPYC Zen 3 "Milan" cores
|

 RSS Feed
RSS Feed