
|
This post is an update to the previous post announcing preview availability of the HPCBOX AutoScaler.
Low Priority Instances
As of 2021-08-17, the HPCBOX AutoScaler includes support for low priority instances. Low priority instances are called by different names on different cloud platforms, spot instance on Azure and AWS, preemptible instance on Oracle OCI.
The general idea being, these instances are the same hardware configuration as the standard instances, but, they can be preempted at any time with a short notification by the cloud vendor. Although these instances can be evicted, they do offer a much lower price and are well suited for jobs which don't have a tight deadline. Ideal Setup
An important functionality for efficient use of low-priority instances is auto-selection and auto-rescheduling. Auto-Selection meaning, we want the right low-priority hardware to be selected based on the job type, for example, we would like to use specific GPGPU nodes for CUDA jobs, dense CPU nodes with high speed interconnect for CFD jobs, etc. Auto-rescheduling means, we would like the system to be able to automatically reschedule jobs when the cloud vendor is about to evict the instances and for applications which support it, we would also like the jobs to be automatically restarted from the last save point.
We are pleased to announce that the HPCBOX AutoScaler supports both these critical functions out of the box. Example Scenario
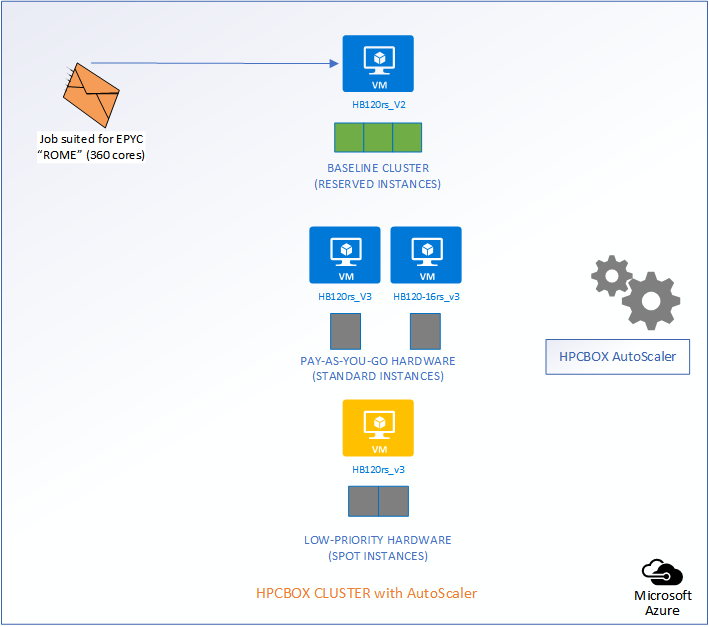
Let us consider a use-case to understand how the Intelligent AutoScaler in HPCBOX handles optimization and efficiently handles combining three different classes of hardware on the same cluster.
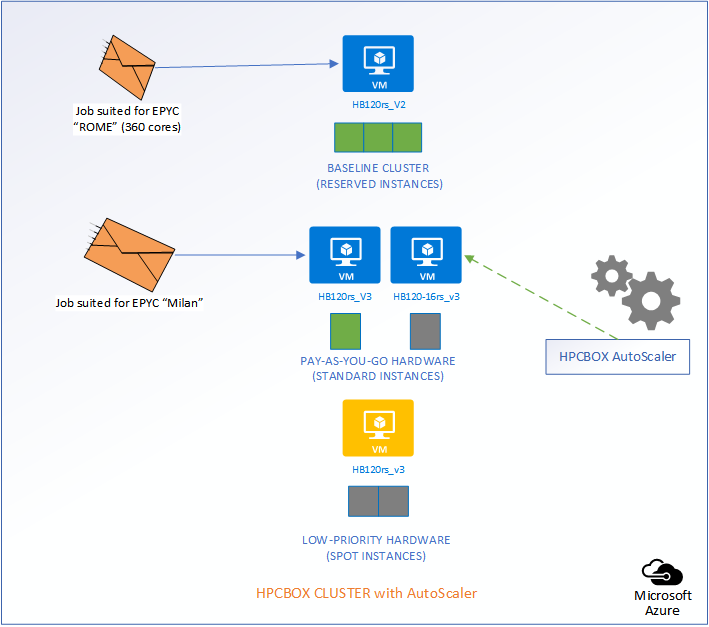
The following picture represents an HPCBOX Cluster which is a combination of both reserved (resources with a usage commitment, on Azure called Reserved Instances), standard pay-as-you-go resources and low-priority resources. To optimize the budget spend in such a configuration, one would want the reserved instances to be always powered-on to provide a baseline capacity for the cluster and automate the use of pay-as-you-go+low-priority resources to minimize resource wastage. Furthermore, we could assume that the compute workers on this cluster are a combination of different hardware configurations, for example, on Azure, we could assume a combination of HB120rs_V2 and HB120-16rs_v3 (combination of AMD EPYC “Rome” and “Milan” hardware). 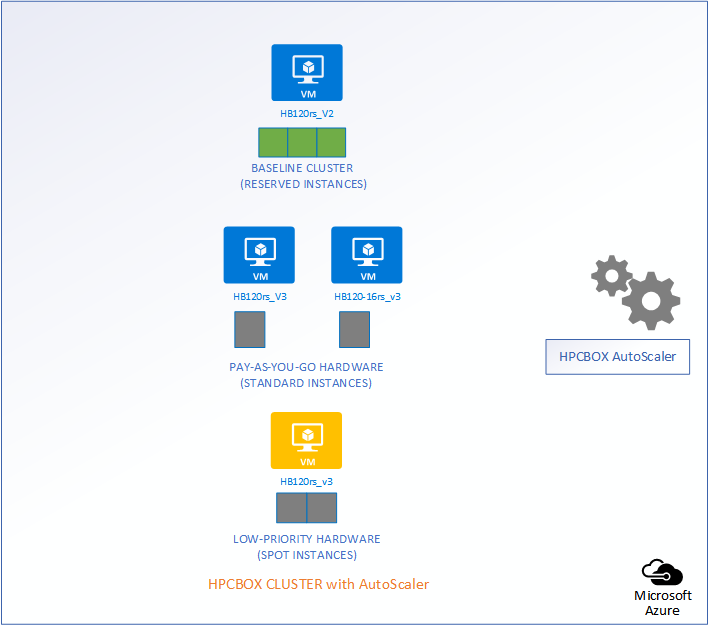
Depending on the type of job that comes into the system, AutoScaler either takes no action, powers on standard rate PAYG hardware, or, low-priority PAYG hardware. It also handles auto power-off of the instances once jobs leave the cluster.
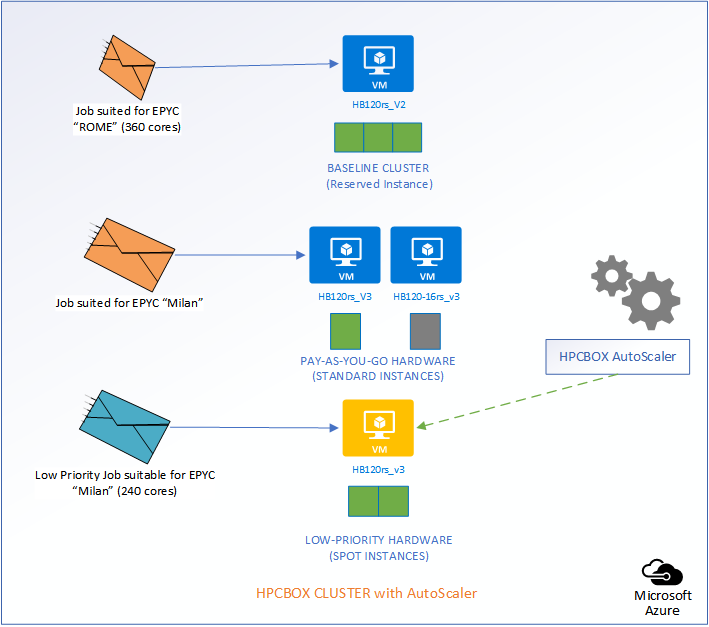
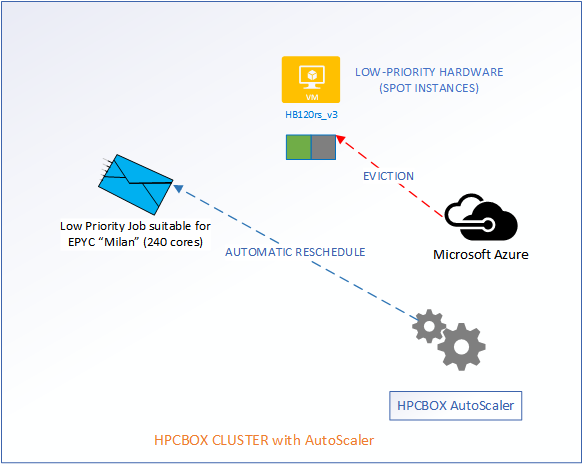
Auto-Rescheduling
When the cloud backbone decides that it needs additional hardware for users who are willing to pay more, our low-priority workers are going to get evicted. However, the AutoScaler makes sure that user jobs get automatically rescheduled without any manual intervention.
Now, comes the best part of the AutoScaler. HPCBOX can automatically attempt restarting of the evicted nodes and when successful, user jobs which got evicted will automatically restart! All this is done with no manual intervention and this, we think, is really how an Intelligent HPC Cloud system should help users optimize their resource usage, deadlines and budgets!
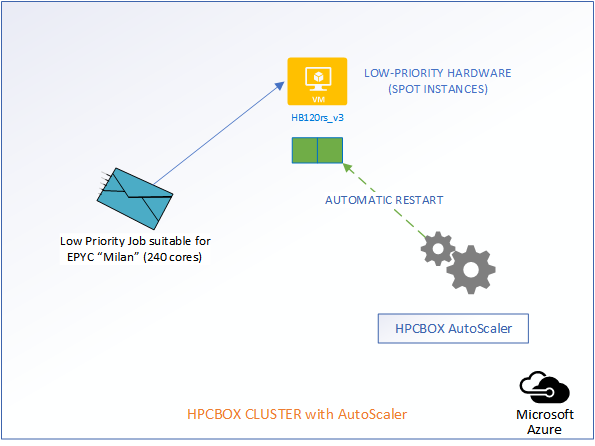
Availability
HPCBOX AutoScaler is now available in preview and we would be very pleased to run a demo or perform a POC or pilot with you to optimize your cloud spend on HPC resources while making sure your jobs are always matched to the most suitable hardware. Schedule a meeting here.

Author Dev S. Founder and CTO, Drizti Inc All third-party product and company names are trademarks or registered trademarks of their respective holders. Use of them does not imply any affiliation or endorsement by them. Comments are closed.
|
 RSS Feed
RSS Feed